We propose FlyKD, a novel, scalable way to compress large Graph Neural Networks
(GNN) to lighter, deployable GNNs. Specifically, FlyKD is a variation of Knowledge
Distillation (KD) method where a larger, more capable teacher model generates
pseudo labels for the student model to learn from.
FlyKD has two novel components in addition to the original KD to address two problems
in Knowledge Distillation in Graphs. The first problem FlyKD addresses is memory isssue of
GNNs. When you generate many pseudo labels using GNNs, users will often run into cuda
Out of Memory (OOM) issue as the student model backpropagates. However,
by generating unseen pseudo labels on the fly with randomness at every epoch, one can generate
virtually infinite amount of pseudo labels for the student model to learn from.
But this poses another problem: pseudo labels are inherently noisy and difficult to optimize.
Generating immense amount of pseudo labels worsens this problem. In order to alleviate this,
FlyKD incorporates a form of Curriculum Learning. Inspired by how humans learn, Curriculum
Learning helps the optimization process of the model by introducing data at an increasing
complexity. To incoporate Curriculum Learning, we use our prior knowledge of noisiness
of each type of labels and gradually introduce them in the order of noisiness.
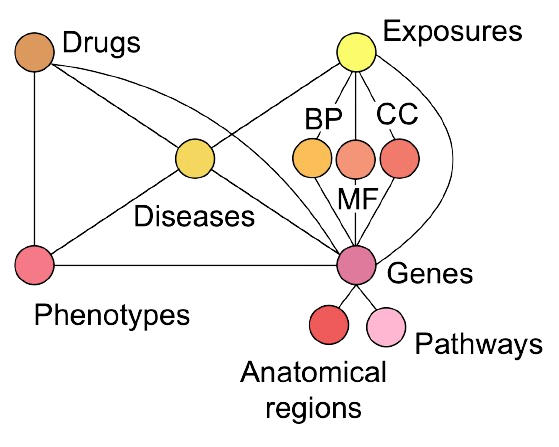
PrimeKG:
Our dataset is composed of the latest biomedical Knowledge Graph called Precision Medicine
Knowledge Graph (Chandak, Huang and Zitnik (2023)), which combines 20+ credible databases such
as DrugBank, DrugCentral, DisGeNet, etc. PrimeKG is specially designed for therepeutic
repurposing of drugs and can be used to find new treatments to diseases that currently
have no treatment.
Furthermore, PrimeKG has over 4 million relations and the scheme of the Knowledge Graph can be illustrated
below (adapted from Chandak, Huang and Zitnik (2023)):
Methods:
FlyKD first trains a teacher TxGNN, zero-shot Relational GCN (R-GCN) developed by (Chandak, Huang and Zitnik
(2023)),
to predict the existence of indication and contraindication relations between drugs and diseases. With
pre-trained teacher TxGNN, we obtain the final node embeddings of the original graph then use the final node embeddings
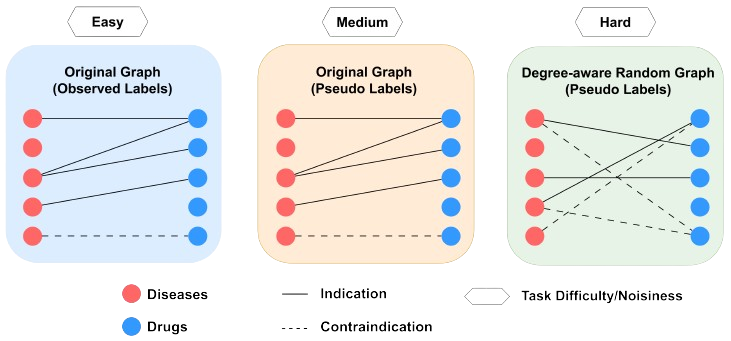
with a scoring function called DistMult to generate three types of labels: Original Label, Pseudo label on Training graph,
and Pseudo label on Degree-aware Random Graph. These three types of labels are illustrated below and ordered by the
level of noisiness.
The recipe for generating Degree-Aware Random Graph is depicted below:
In plain words, GenerateRandomGraph selects two nodes where the probability of a
node being selected is proportionate to the degree of a node in the original graph (with
respect to the relation). By doing so, we increase the quality of the pseudo labels on the
random graph by utilizing the prior information that nodes that have seen more labels
during training are more likely to have a higher embedding quality. Once two nodes are
selected, a link is formed between them. This process of generating pseudo links is repeated
k times.
The above generation of random graph per epoch conceptually enables the teacher model to generate
unlimited number of pseudo labels that can be backpropgated by the student model.
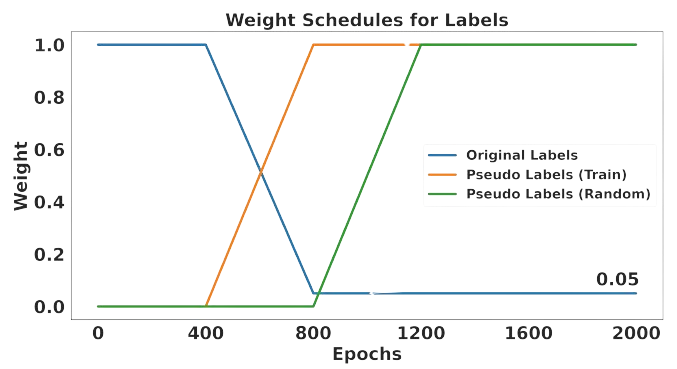
As mentioned earlier, pseudo labels are inherently noisy and pseudo labels on random graphs are
even more noisy. Thus, we incorporate a form of Curriculum Learning by utilizing a loss scheduler,
which gradually shifts the emphasis from easy original label to medium pseudo label on train graph and
ultimately hard pseudo label on the random graph. The loss scheduler is depicted below:
Results:
Here are the baseline models' performances where TxGNN 130 represents the more capable teacher model and
TxGNN 80 represents the lighter student model.
Baseline AUPRC (%):
Model
Num. Params
Seed 45
Seed 46
Seed 47
Seed 48
Seed 49
Mean ± std
Baseline 130
(1.7M)
80.33
73.66
76.29
84.19
79.91
78.87 ± 4.04
Baseline 80
(650k)
78.64
71.97
74.44
82.74
77.87
77.13 ± 4.13
There is a high variance of performance due to zero-shot
evaluation setting. Thus, we focus on the relative performance gains at each seed and average across seeds.
This way, we can more accurately attribute changes in performance to the methods themselves,
rather than to fluctuations in task difficulty associated with different seeds.
In our study, we delve into three distinct methods of Knowledge Distillation (KD) for Graph Neural Networks (GNN):
Basic Knowledge Distillation (BKD) as introduced by Hinton, Vinyals, and Dean in 2015,
Local Structure Preserving GCN (LSPGCN, also known as DistillGCN) developed by Yang et al. in 2020,
and our innovative approach, FlyKD.
Knowledge Distillation Methods (Relative gains from Baseline80)
Model
Time
Curriculum Learning
Mean±std
Basic KD
1600
No
-0.62±0.59
LSP 1 layer (RBF)
20000
No
-1.09±0.23
LSP 2 layers (RBF)
40000
No
-1.41±0.82
FlyKD
2000
Yes
1.16±0.36
Our experiments reveal that while BKD and LSPGCN result in negative KD effects,
FlyKD stands out by achieving positive relative gains. We find out the reason for such gap in the following
ablation study.
Ablation study (Relative gains from Baseline80)
Model
Configuration
Mean±std
Basic KD
Employ Curriculum Learning
0.93±0.45
FlyKD
Fix Random Graph
1.14±0.39
FlyKD
No Curriculum Learning
0.19±0.42
FlyKD
Take Out Pseudo Labels on Train Dataset
-0.68±0.63
FlyKD
stepwise function for Curriculum Learning
-1.436±0.86
Our ablation study shows that noise in the teacher model's pseudo labels causes the performance gap between FlyKD and other KD methods.
Adding Curriculum Learning to BKD improves its performance noticeably, giving a +1.55% boost over the standard approach.
Findings
Optimization process of the student model in KD is inherently noisy, and Curriculum Learning can greatly alleviate this issue.
Curriculum Learning for KD requires a gradual change in difficulty, corroborated by catastrophic degradation in performance when a step-wise loss scheduler is employed instead.
LSPGCN is not scalable for Knowledge Graphs, as demonstrated by a 10-20x increase in time as shown in Table 2. This holds true for most Knowledge Distillation methods tailored for graphs with similar mechanisms.
FlyKD’s pseudo labels on degree-aware random graphs seem to help but do not provide any additional gains beyond the generation of one random graph and maintaining it, instead of generating a new random graph at every epoch throughout the training. Further investigation is needed to understand this phenomenon.
Last Remark:
We believe our experimental results suggest a new research direction of how to improve the
optimization process of the student model rather than the common what pseudo labels to
generate (What to distill).
FlyKD
Graph Knowledge Distillation on the Fly with Curriculum Learning